One-Hot Mux
ZipCPU recently posted about working around some poor synthesis results for a kind of mux that I’m going to refer to as a one-hot mux. A one-hot mux is where the control signal that selects which of the mux inputs to output is a one-hot vector of width equal to the number of mux ports. This is opposed to a normal mux where the control signal is a binary index selecting one of the ports, which I’m going to call an indexed mux for the rest of this post.
The post really got me curious, as I had some similar looking code open in my editor that day, and I didn’t really think the performance of a one-hot mux would be that much worse than an indexed mux. So let’s take a look!
A typical place you might run into a one-hot mux construct is when merging results from multiple buses back onto a master bus. For example if you have multiple peripheral devices that you place behind a Wishbone interface with address decoding to dispatch requests, the result of each request, from each device, needs to be placed back onto the Wishbone bus. Each bus has a data path and a valid signal, and you need to merge those N data vectors and N valid signals down to a single data vector and valid signal.
Obviously you need to design in something to ensure that there will not be two results colliding. For example you might only have one outstanding request at a time, so that only one of the devices is ever active, as was the case in ZipCPUs post. Alternatively your protocol might have a fixed latency for all devices, so you know that as long as one request is issued per cycle then only one response will return per cycle.
In the case where a single request is outstanding, or in other cases where it is easy to pre-calculate or remember which device is addressed, you could store the index of the device that we expect the response to come from and use a normal indexed mux. This is probably the best solution where possible, as FPGA vendors place a high priority on indexed mux performance. Xilinx devices, for example, feature dedicated HW muxes behind the LUTs in a slice to help build fast, wide muxes.
But in other situations it is not so easy to keep track of where the next response will come from. If we pipeline requests to devices that have a long, fixed latency, for example, we would need an equally long shift register to remember where the next response will come from.
So, here’s some straight forward code for a one-hot mux. Note: this is not optimal!
p_oh : process(clk)
begin
if rising_edge(clk) then
oh_data <= '0';
oh_valid <= '0';
for i in 0 to G_PORTS-1 loop
if valid(i) = '1' then
oh_valid <= '1';
oh_data <= data(i);
end if;
end loop;
end if;
end process p_oh;
This gives us what we want, so long the valid vector is one-hot. But this does not synthesize well! For a single bit of oh_data and an 8-wide mux we consume 6 LUTs, 2 deep on a LUT6 architecture:
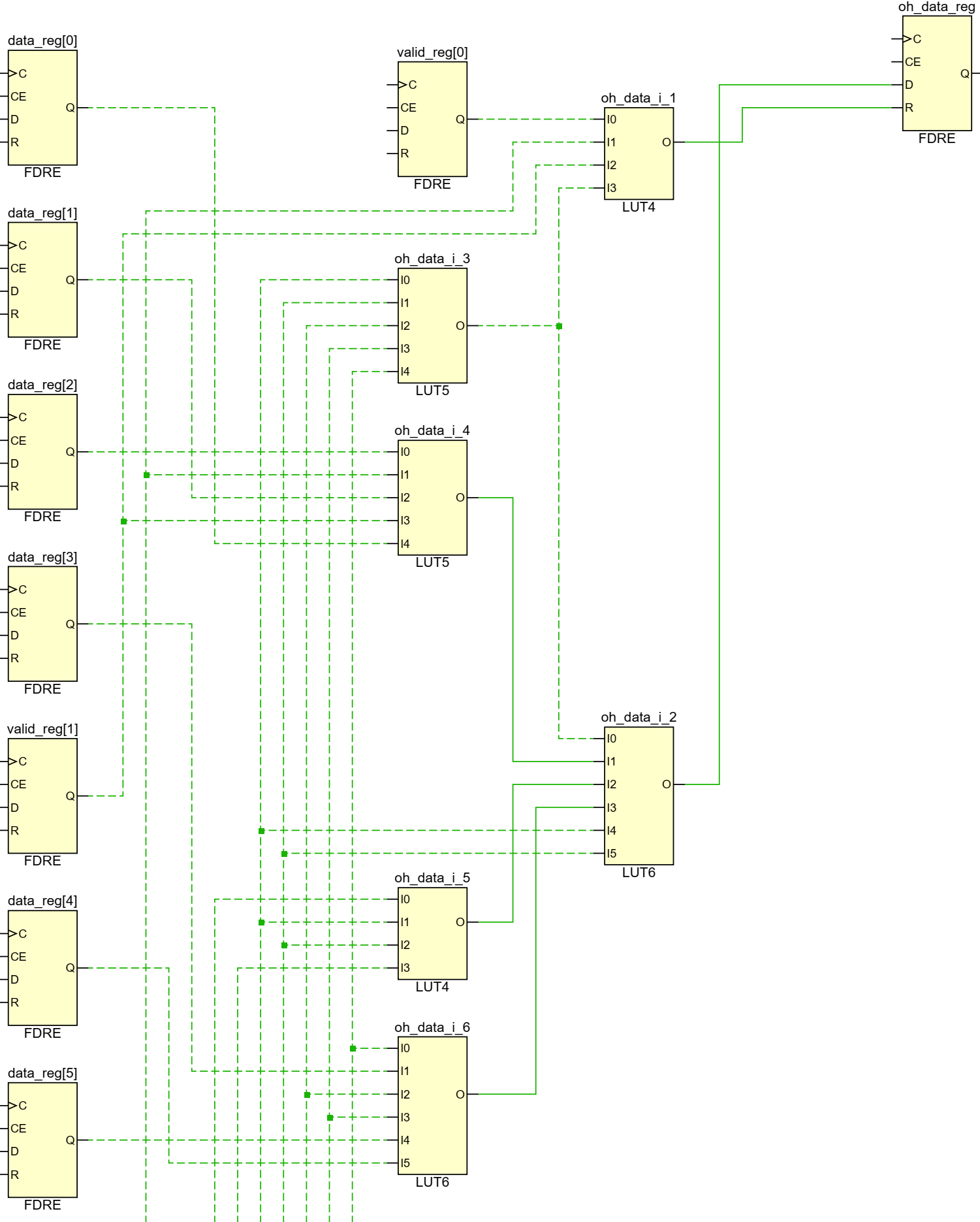
And it doesn’t scale well either:
- An 8-way mux consumes 6 LUTs, 2 deep.
- A 16-way mux consumes 17 LUTs, 3 deep.
- A 64-way mux consumes 55 LUTs, 4 deep.
What are we actually synthesizing? Let’s unroll the loop for G_PORTS = 8:
p_oh : process(clk)
begin
if rising_edge(clk) then
if valid(7) = '1' then
oh_valid <= '1';
oh_data <= data(7);
elsif valid(6) = '1' then
oh_valid <= '1';
oh_data <= data(6);
elsif valid(5) = '1' then
oh_valid <= '1';
oh_data <= data(5);
elsif valid(4) = '1' then
oh_valid <= '1';
oh_data <= data(4);
elsif valid(3) = '1' then
oh_valid <= '1';
oh_data <= data(3);
elsif valid(2) = '1' then
oh_valid <= '1';
oh_data <= data(2);
elsif valid(1) = '1' then
oh_valid <= '1';
oh_data <= data(1);
elsif valid(0) = '1' then
oh_valid <= '1';
oh_data <= data(0);
else
oh_data <= '0';
oh_valid <= '0';
end if;
end if;
end process p_oh;
A naïve construction of this logic would be a chain of 8 2:1 muxes. Let’s convert it to a truth table:
p_oh : process(clk)
begin
if rising_edge(clk) then
case valid is
when "00000000" => oh_valid <= '0'; oh_data <= '0';
when "00000001" => oh_valid <= '1'; oh_data <= data(0);
when "00000010" => oh_valid <= '1'; oh_data <= data(1);
when "00000011" => oh_valid <= '1'; oh_data <= data(1); -- Illegal state
when "00000100" => oh_valid <= '1'; oh_data <= data(2);
when "00000101" => oh_valid <= '1'; oh_data <= data(2); -- Illegal state
when "00000110" => oh_valid <= '1'; oh_data <= data(2); -- Illegal state
when "00000111" => oh_valid <= '1'; oh_data <= data(2); -- Illegal state
-- ... <snip/> ...
when "11111111" => oh_valid <= '1'; oh_data <= data(7); -- Illegal state
end case;
end if;
end process p_oh;
Well, part of a truth table. I’m not going to write out 256 when statements! And here we start to see what is sub-optimal about our current code: it specifies a particular result in a whole bunch of states that we will never be in, by design, and hence don’t care actually care about. The code is over-specified! And, in fact, it implements not a one-hot mux, but a priority mux, where inputs with higher index take priority over inputs with lower index. No wonder we are using more logic than we need to.
The problem is that the synthesis tools do not know that our valid vector is one-hot. We need to change our code to either specify what cases we do and don’t care about, or we need to find better logic ‘manually’ so that the code expands to a truth table that synthesizes into fewer LUTs.
The Manual Way
At my first HDL workplace our designs used an internal bus similar to Wishbone for many of our components. Part of the specification of that bus protocol was that the response data vector had to be set to all 0 whenever the response valid bit was 0. When I asked why I was told “So we can just OR the buses together!”
And that’s exactly what we did. A response bus mux then looked like this:
p_oh : process(clk)
variable v_valid : std_logic := '0';
variable v_data : std_logic := '0';
begin
if rising_edge(clk) then
v_data := '0';
v_valid := '0';
-- Assume data(i) = '0' when valid(i) = '0'
for i in 0 to G_PORTS-1 loop
v_valid := v_valid or valid(i);
v_data := v_data or data(i);
end loop;
oh_valid <= v_valid;
oh_data <= v_data;
end if;
end process p_oh;
This is an excellent solution if you have full control over the bus protocol and/or all of the devices on the bus. It is relatively easy (and cheap) to add code to reset the output register of each device, to the same branch of of code that is setting valid = ‘0’ when there is no response. The one-hot mux becomes very cheap, as the data logic is independent of the valid logic. It can actually consume less LUTs than an indexed mux.
We can’t use this directly if we don’t have control over all of the devices, but it does suggest a solution:
p_oh : process(clk)
variable v_valid : std_logic := '0';
variable v_data : std_logic := '0';
begin
if rising_edge(clk) then
v_data := '0';
v_valid := '0';
for i in 0 to G_PORTS-1 loop
v_valid := v_valid or valid(i);
v_data := v_data or (valid(i) and data(i));
end loop;
oh_valid <= v_valid;
oh_data <= v_data;
end if;
end process p_oh;
Here we mask out each data bus with the corresponding valid signal before ORing the data together. For a 1-bit 8-way mux we still need to look at 16 input bits (8x data and 8x valid), but this now decomposes into a well balanced logic tree, and ideally need only consume 3 LUTs, 2 deep on a LUT6 architecture:
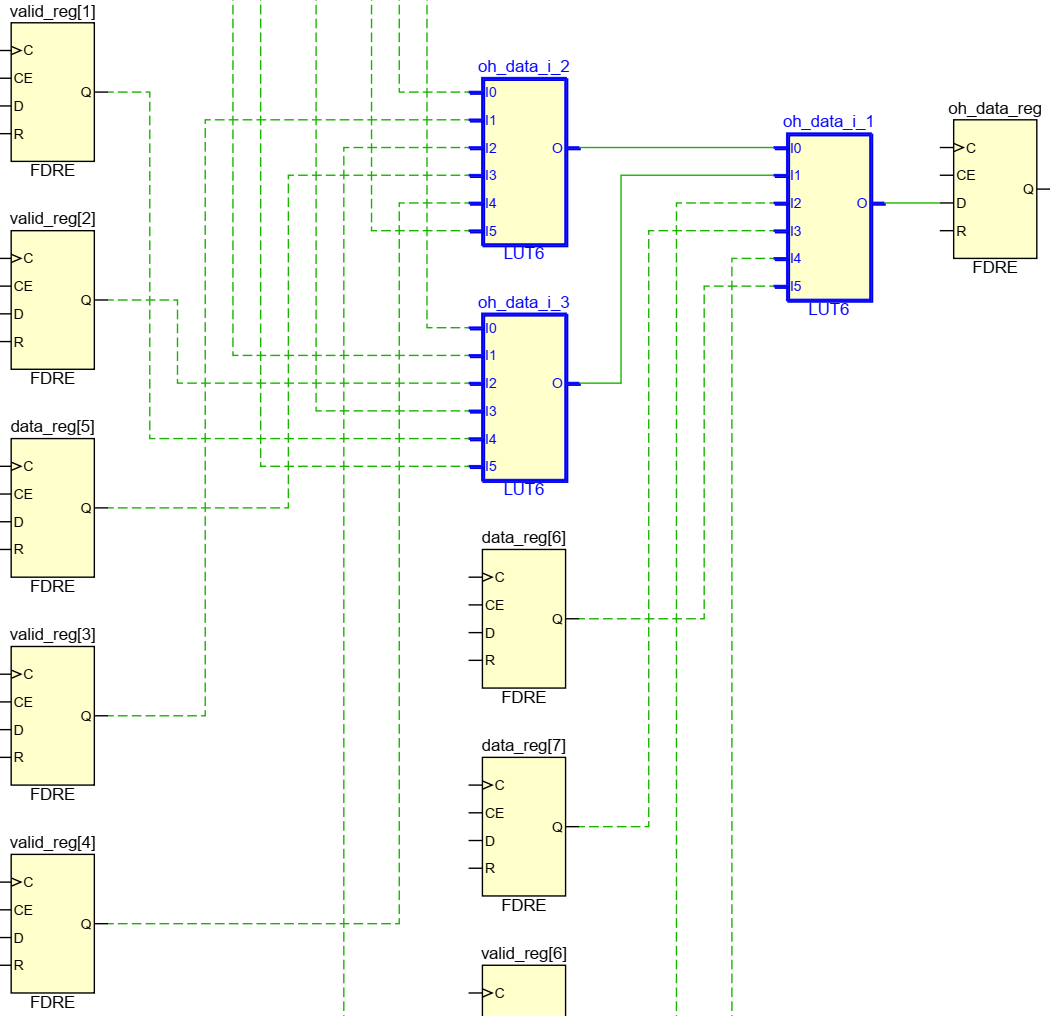
However, for some reason I don’t understand, Vivado implements this instead using 5 LUT4s, 2 deep. It does this even if I remove the loop and write out the full logic expression for an 8-way mux. I thought maybe Vivado was pushing for faster timing by using the O5 output from each LUT4, but a 16-way mux consumes 8 LUTs, 3 deep, when it could instead be implemented as 7 LUTs, 2 deep, so timing can’t be the reason. Then I thought maybe Vivado was trying to keep from losing too many flipflops, as maybe using a full LUT6 renders one of the flipflops inaccessible to other uses? But while this was the case in 7-series FPGAs, the Ultrascale device I am targeting has dedicated inputs to both flipflops independent of how the LUT is used. So I have no excuses for why Vivado is implementing it like this:
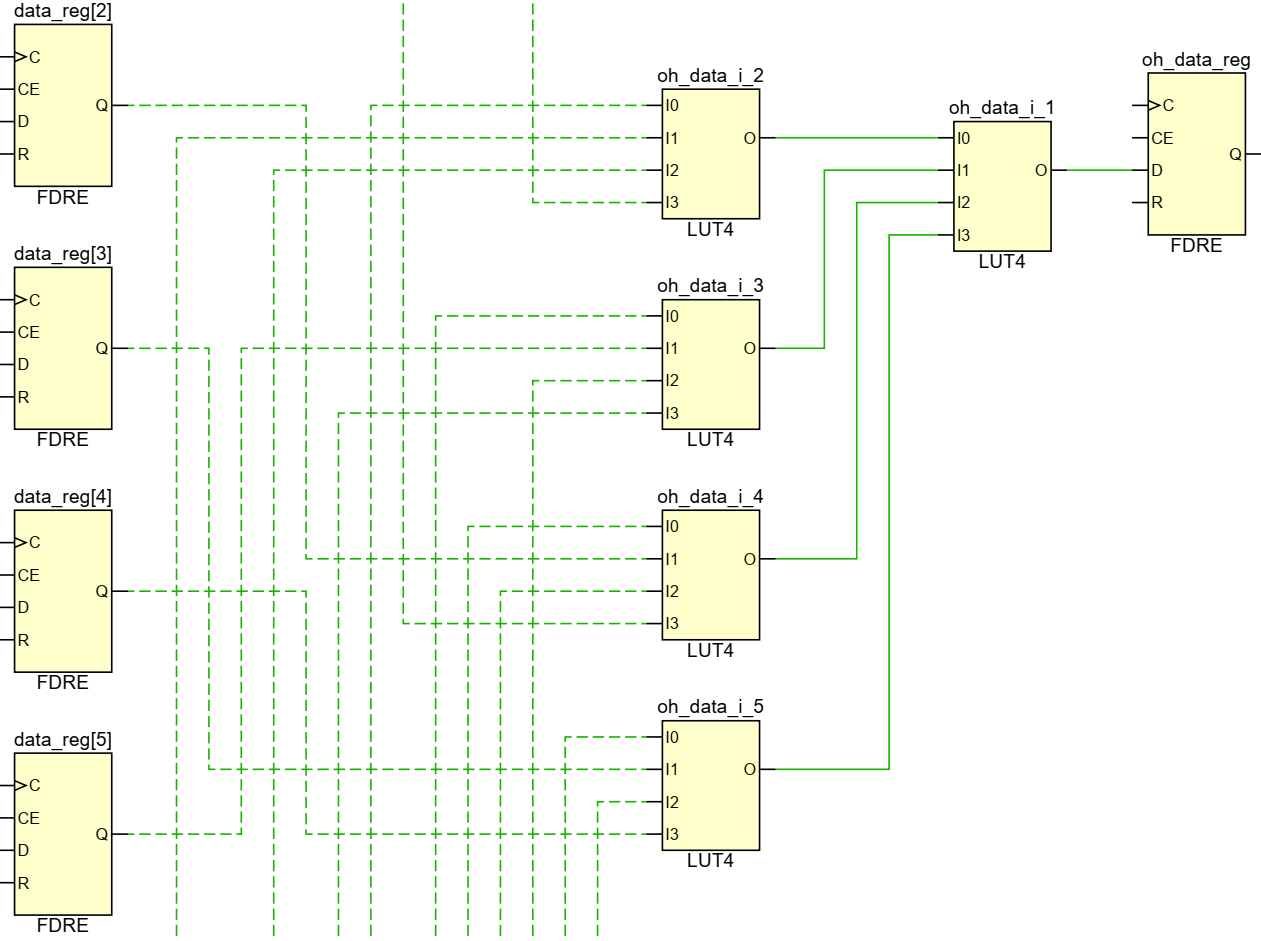
The Automatic Way
It would be better if we didn’t have to find a nice logic function that synthesizes well for all the cases we don’t care about. We have lots of cases we don’t care about, and VHDL has a don’t care literal, so let’s see how that goes.
(I actually have very little experience using don’t care ‘-‘ as none of the teams I have worked on have used it. I’m not sure why, perhaps it was poorly supported by some tools in the past. Perhaps it still is. This seems to indicate the same.)
Our goal is to specify only those cases we actually care about, and leave all others as don’t care. We would like to end up with a truth table that looks like this:
p_oh : process(clk)
begin
if rising_edge(clk) then
case valid is
when "00000000" => oh_valid <= '0'; oh_data <= '-';
when "00000001" => oh_valid <= '1'; oh_data <= data(0);
when "00000010" => oh_valid <= '1'; oh_data <= data(1);
when "00000100" => oh_valid <= '1'; oh_data <= data(2);
when "00001000" => oh_valid <= '1'; oh_data <= data(3);
when "00010000" => oh_valid <= '1'; oh_data <= data(4);
when "00100000" => oh_valid <= '1'; oh_data <= data(5);
when "01000000" => oh_valid <= '1'; oh_data <= data(6);
when "10000000" => oh_valid <= '1'; oh_data <= data(7);
when others => oh_valid <= '1'; oh_data <= '-';
end case;
end if;
end process p_oh;
If we synthesize this code as-is, we in fact get very good results. Here we actually get the ideal result with 3 LUTs, 2 deep, as we would get by hand-optimizing our previous code. If we look at the truth tables in the LUTs we actually find the same logic has been inferred: an OR tree of (data AND valid). This is great!
It also produces ideal logic for a 16-way mux, using 7 LUTs, 2 deep. Great! But for a 64-way mux it consumes 35 LUTs, 4 deep, when it could be implemented in 26 LUTs, 3 deep. Not so great.
But this code isn’t generic over the number of mux ports. So we try to make it so:
p_oh : process(clk)
begin
if rising_edge(clk) then
oh_data <= '-';
v_valid := '0';
for i in 0 to G_PORTS-1 loop
v_valid := v_valid or valid(i);
if (2**i) = unsigned(valid) then
oh_data <= data(i);
end if;
end loop;
oh_valid <= v_valid;
end if;
end process p_oh;
Here we expand the loop variable to a power-of-two integer and then compare the entire valid vector to it. That means we should only hit the true condition when valid is in fact one-hot, and otherwise the value of oh_data should remain as don’t care. If we manually expand this to a chain of if-elses and then to a truth table case statement, we should end up with a generic version of the code we wrote above. I actually thought this was roughly how synthesis worked, and that this would give good results. Alas, it does not:
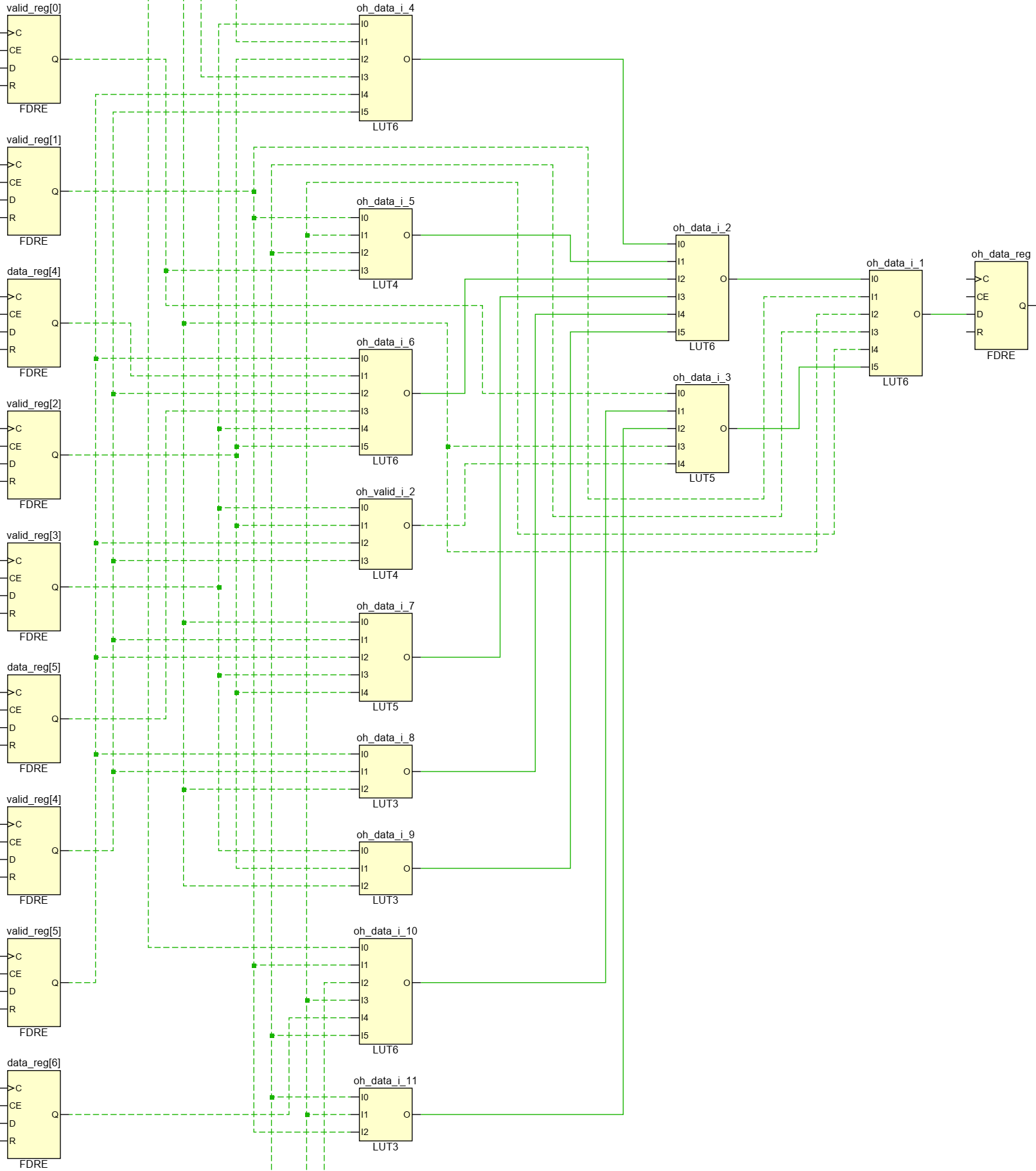
I don’t even know what logic function this is implementing. It is using 12 LUTs, 3 deep, to implement something it could be doing in 3 LUTs, 2 deep. The same code for a 16-way mux uses 44 LUTs, 5 deep!
Next I tried something a bit more explicit, using a function to test for one-hot-ness:
-- Returns true iff vec has the idx'th bit = 1 and all other bits = 0
function f_one_hot(vec : std_logic_vector; idx : integer) return boolean is
variable r : boolean := true;
begin
r := true;
for i in vec'low to vec'high loop
if (i = idx and vec(i) = '0') or (i /= idx and vec(i) = '1') then
r := false;
end if;
end loop;
return r;
end function f_one_hot;
begin
p_oh : process(clk)
begin
if rising_edge(clk) then
oh_data <= '-';
v_valid := '0';
for i in 0 to G_PORTS-1 loop
v_valid := v_valid or valid(i);
if f_one_hot(valid, i) then
oh_data <= data(i);
end if;
end loop;
oh_valid <= v_valid;
end if;
end process p_oh;
But this synthesizes to exactly the same thing as the power-of-two above.
So I tried once more, this time explicitly looking for two-or-more bits set in the valid vector and setting the data to don’t care after the loop when this happens:
p_oh : process(clk)
variable v_valid : std_logic := '0';
variable v_one : std_logic := '0';
variable v_two : std_logic := '0';
begin
if rising_edge(clk) then
oh_data <= '-';
v_valid := '0';
v_one := '0';
v_two := '0';
for i in 0 to G_PORTS-1 loop
v_valid := v_valid or valid(i);
if valid(i) = '1' then
oh_data <= data(i);
if v_one = '1' then
v_two := '1';
end if;
v_one := '1';
end if;
end loop;
oh_valid <= v_valid;
if v_two = '1' then
oh_data <= '-';
end if;
end if;
end process p_oh;
This synthesizes a lot better, for some reason. We end up using 5 LUTs, 2 deep for an 8-way mux and 11 LUTs, 3 deep for a 16-way mux. Neither of these are optimal, but they are not as terrible as the two previous attempts.
And that’s where I get stuck. I can’t think of a generic way to specify only one-hot cases that Vivado manages to use efficiently. So, for this case of one-hot mux I would fall back on the manual logic specification and know that I will get decent results, but for the general case of generic code with lots of don’t care cases I don’t have an easy and effective strategy.
Perhaps other tools work better than Vivado here. I’d like to try the same things in Yosys, especially considering that I can examine the source and trace the logic generation to see whats going on in a way that I can’t with Vivado. Next time.